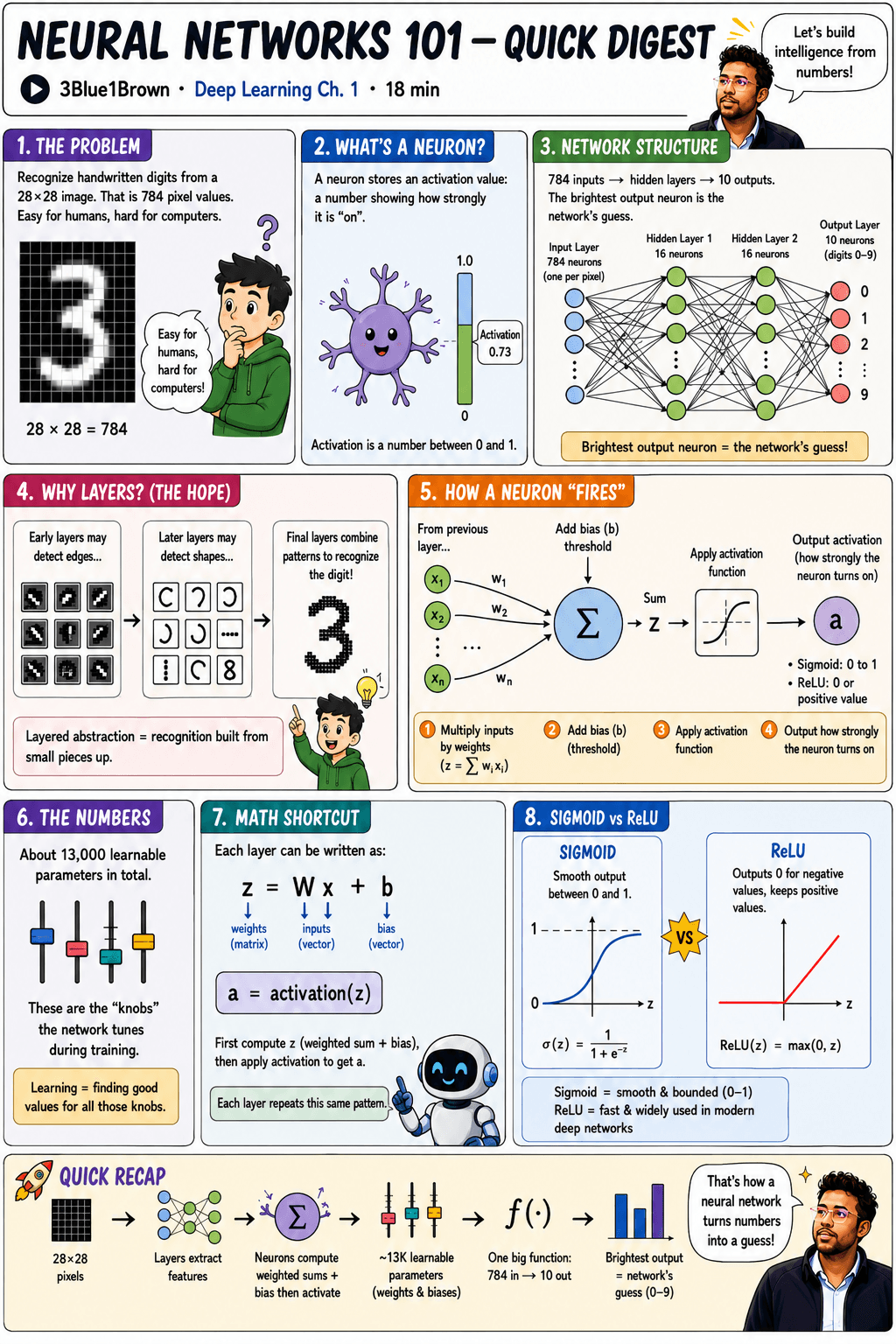
I just finished watching 3Blue1Brown’s “But what is a neural network?”. It’s the first chapter of Deep Learning series. It’s 18 minutes, and it’s one of the clearest explanations of neural networks I’ve ever come across.
To make sure the ideas actually stuck, I sketched out an infographic of the whole video. This post is me walking through what I learned, in plain English. If you’ve ever wondered what’s actually happening inside a neural network, this is for you.
- What a neuron actually is (it's just a number)
- How layers are structured and why they exist
- How a single neuron computes its output
- What "learning" actually means (weights + biases + training)
The problem: easy for humans, hard for computers
The whole video is built around one deceptively simple task: recognize a handwritten digit from a 28×28 pixel image.
That’s 784 pixel values. You and I can glance at a wobbly “3” and instantly know it’s a 3. A computer just sees 784 numbers between 0 (black) and 1 (white). How do you go from “a list of 784 numbers” to “that’s a 3”?
That’s the puzzle a neural network solves.
What’s a neuron?
Ignore the brain analogy for a minute. A neuron is just a thing that holds a number between 0 and 1. This number is called its activation.
- 0.0 → completely off
- 0.73 → pretty active
- 1.0 → fully lit up
That’s it. A neuron is a number in a box.
The network structure
A network can have any number of layers. The network in this video has four:
- Input layer: 784 neurons — one per pixel. Each one’s activation is the brightness of that pixel.
- Hidden layer 1: 16 neurons.
- Hidden layer 2: 16 neurons.
- Output layer: 10 neurons — one per digit (0 through 9).
You feed an image into the 784 input neurons, the activations ripple forward through the hidden layers, and you end up with 10 numbers at the output. Whichever output neuron lights up brightest is the network’s guess.
If output neuron #3 has the highest activation, the network is saying “I think this is a 3.”
Why layers? (The hopeful story)
Why bother with hidden layers? Here’s the idea behind them. Fair warning though, real networks don’t always work out this cleanly:
- Early layers might detect tiny edges and strokes.
- Middle layers might combine those edges into shapes — loops, curves, lines.
- Later layers might combine those shapes into full digits.
It’s recognition built from the bottom up. Pixels → edges → shapes → digits. Layered abstraction.
How a single neuron “fires”
Here’s the core mechanic. Every neuron in a hidden or output layer does the same four-step process:
- Multiply each input by a weight. Every connection from the previous layer has a weight (
w₁, w₂, … wₙ). The neuron multiplies each incoming activation by its weight and adds them all up:z = Σ wᵢxᵢ. - Add a bias. The bias
bis a threshold — it shifts the result up or down. Think of it as saying “only fire if the weighted sum is meaningfully positive” (or negative, depending on the bias). - Apply an activation function. The raw sum
zcould be any number. The activation function squishes it into a sensible range. - Output the result as the neuron’s activation
a.
Weights tell the neuron what to look for. Biases tell it how picky to be.
The numbers (this is the wild part)
How many of these weights and biases are there in this little digit-recognizer?
About 13,000.
Each one is a parameter. Learning means tuning all 13,000 of them until the network gives the right answer. That’s it. That’s machine learning. When people say a model is “trained,” they mean someone (or rather, an algorithm) found a decent setting for every one of those parameters.
The math shortcut
Doing 13,000 multiplications by hand sounds awful. The good news: each layer can be written as a single tidy equation:
z = W·x + b
a = activation(z)
Wis a matrix of all the weights for that layer.xis the vector of inputs from the previous layer.bis the vector of biases.activation(z)applies the activation function element-by-element.
Every layer is just that. Matrix multiply, add a vector, squish through a function. Repeat. The whole network is a stack of these operations — which is exactly why GPUs (which are very, very good at matrix math) eat this stuff for breakfast.
Sigmoid vs. ReLU
The activation function is the “squishing” step. The video introduces two:
| Sigmoid | ReLU | |
|---|---|---|
| Formula | σ(z) = 1 / (1 + e⁻ᶻ) |
ReLU(z) = max(0, z) |
| Output range | (0, 1) | [0, ∞) |
| Shape | Smooth S-curve | Hockey stick |
| When used | Classic / historic | Modern deep networks |
| Downside | Slow to train in deep nets | — |
Sigmoid was the textbook choice for decades. ReLU is the workhorse of modern deep learning.
Quick recap
Here’s the whole pipeline:
- Input: 28×28 pixels = 784 numbers fed into the input layer
- Propagate: activations ripple forward through hidden layers, each neuron computing a weighted sum + bias → activation function
- Parameters: ~13,000 learnable weights and biases shape the whole computation
- Output: one big function — 784 numbers in, 10 numbers out
- Guess: whichever output neuron is brightest is the network’s answer
A neural network really is just one big function. A function that takes 784 numbers in and spits 10 numbers out. The “learning” part is finding the right 13,000 internal numbers so that function gives sensible answers.
What I’m taking away from this
A few things clicked for me watching this video:
- A neural network isn’t magic. It’s a giant pile of multiplications and additions wrapped in a squishing function.
- “Layers learning features” is a hopeful story, not a guarantee and that’s an honest thing to admit upfront.
- The hard problem isn’t the architecture. It’s finding good values for those 13,000 parameters. That’s where the next chapters of the series come in: gradient descent and backpropagation.
If this got you curious, watch the original video. It’s worth all 18 minutes. And then watch chapters 2 and 3, because that’s where the real magic (gradient descent) shows up.
This post was inspired by 3Blue1Brown’s Deep Learning series, Chapter 1. The infographic above is my own visual summary of the video.